Let’s talk about what happens when things go wrong.
Regardless of which internet service provider (ISP) you are with, at some point in time you will experience an outage. This could be due to a fibre cut, a failure on the part of the ISP (there are a million things that can go wrong), a problem with the router you use, or any number of other things.
The point is, it will happen.
While we continue to do everything in our ability to add ever more resiliency to our network, and even though we provide a level of uptime that we are proud of and that enables us to provide critical services to some of New Zealand’s and Australia’s biggest companies (just had to talk us up a little there), our customers will also experience outages on occasion.
What happens when an outage kicks in?
First things first, all services are monitored by Pulse, which will ensure that within 5 minutes of an outage commencing the technical contact(s) for the account in question will receive an email, a ticket is created, and if this occurs during business hours we will be calling the tech contact(s) to see what we can do to assist.
If you are wondering what happens out of hours, we create the ticket and send the email, but we ask that customer call us if they would like us to investigate ASAP as it is very possible that the outage relates to planned work.
The key point here is that all Lightwire services are managed services.
What about widespread outages?
An issue that sees two or more unrelated accounts affected now triggers a new process, which is really the point of this blog post. This new process was developed after taking on board feedback from Tristram at Tech Management Group after one such outage which occurred a few months back. In that particular case, our comms really weren’t up to scratch.
The key issues/questions we needed to address were:
When a NOC team member starts a shift, how do they know an event is ongoing?
How do we ensure all staff know there is an event in play from the moment it kicks in to ensure uniform delivery of detail to clients across the organisation?
Equally, how does everyone know when it is resolved?
How do we inform affected clients the moment we become aware without slowing down the resolution process?
Ensuring a clear process is followed and communicated so clients are certain if/when an outage has been permanently resolved.
To solve all of this, we came up with the concept of a big red button.
The big red button process
Step 1: As soon as a Lightwire staff member is aware of an unplanned outage or fault the big red button on the lefthand side is pressed.
The big red button is only viewable for Lightwire staff and is used to alert the organisation of an unplanned outage or fault.
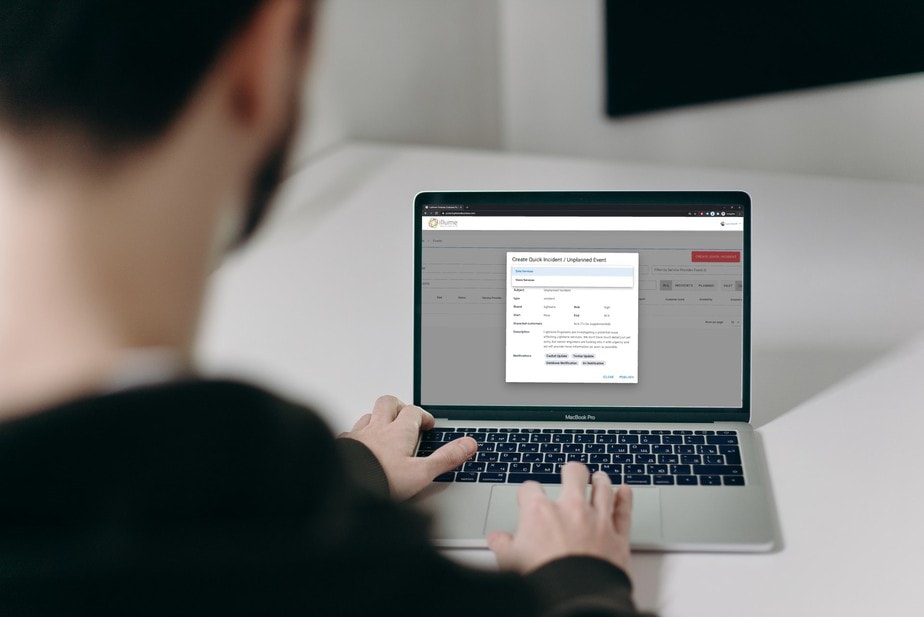
Step 2: The quick incident/unplanned event window pops up and the Lightwire engineer creates the incident for the relevant service.
Lightwire staff can quickly create an incident or unplanned event and update relevant stakeholders.
Step 3: At this stage we are looking to ensure you know that we are aware of an event and are working on it. We probably won’t have a lot of detail at this stage, so the content is pretty simple. The customer facing alerts are sent out via email, illume, Twitter, and SMS to notify customers of the incident or unplanned event.
Lightwire email for incident or unplanned event alert
Logging into illume, our customer protal, you will see an alert published for the incident or unplanned event.
Lightwire Tweet for incident or unplanned event alert. Follow @LightwireAlerts to get notified of all incidents or unplanned events.
Step 4: The incident is (only) internally displayed on every page. Clicking on the incident allows Lightwire staff to see the latest info around the event. illume is core to how Lightwire staff work and this feature puts connectivity issues front and centre – making sure no outage goes is missed.
Step 5: As engineers determine the cause of the incident and start taking steps to remediate, updates are sent to affected users via email/SMS and our events tool as details come to light.
Once we are sure that the problem is fixed and services are restored for affected customers, we mark the incident as resolved in our event tool.
This sends a final update to customers with an event status of resolved and marks the event resolved on Twitter and our status page
The wait is over! 3CX Version 20, Update 6 is now available, bringing with it some exciting new features and powerful improvements to reporting, call logs, and direct data access. We give you the lowdown of what you’ll see with 3CX v20 Update 6.
In addition to static addresses and PPPoE, Lightwire Business Ultrafast Broadband (UFB)* connections can now automatically receive IP addresses using Dynamic Host Configuration Protocol (DHCP).